5. Observations and Conclusion¶
As we mentioned earlier, it is not possible for us to have a Grad-CAM visualization for a segmentation network, since it does not output probability scores like a classification network. What we will do now is a comparative analysis based on our subjective observations having observed Grad-CAM and Grad-CAM++ visualization on classification networks. We then observe the semantic and instance segmented maps on these images and see how good the inferences were.
Warning
The Grad-CAM visualizations are from Classification models, and they have no direct co-relation with segmentation maps. We simply observe the interpretable nature of classification models and extend the conclusions on segmentation models. If you recollect, Semantic Segmentation = Classification + Localization and Instance Segmentation = Semantic Segmentation + Object Detection. Therefore, we argue that any interpretable results we acquire for classification gets carried forward to Segmentation too due to this inverse correlation. This work is not a direct observations of Interpretable Segmentation models.
Before we jump into our observations, its important to note than we used pretrained models provided by PyTorch for our work. More specifically, we used:
1. fcn_resnet101 (FCN network with ResNet-101 backbone) and deeplabv3_resnet101 (DeepLab-v3 Atrous Convolution based network again with ResNet-101 backbone)
for Semantic Segmentation tasks. These models were trained on subset of COCO 2017 PASCAL VOC dataset with just 20 categories.
2. maskrcnn_resnet50_fpn (Feature Pyramid Pooling based Mask-RCNN network with ResNet-50 backbone) for Instance Segmentation tasks. This model was trained
on 80 categories of the COCO 2017 PASCAL VOC dataset.
3. vgg-16, vgg-19, resnet-50, resnet-101 and resnet-152 based classification pretrained models for our Grad-CAM and Grad-CAM++ visualizations.
All the classification models were trained on IMAGENET-1000 dataset with 1000 classes.
Grad-CAM and Grad-CAM++ visualizations of VGG-16 network for layer 43 along with Segmentation outputs
¶
Now, that we know how our models were trained on, we observed that our experiment set shrunk to just 20 categories. This is because, semantic segmentation models were trained on only 20 categories and any image with a category not trained on the ones provided was automatically segmented as background. For sanity purposes, we took images from only those categories for our tests.
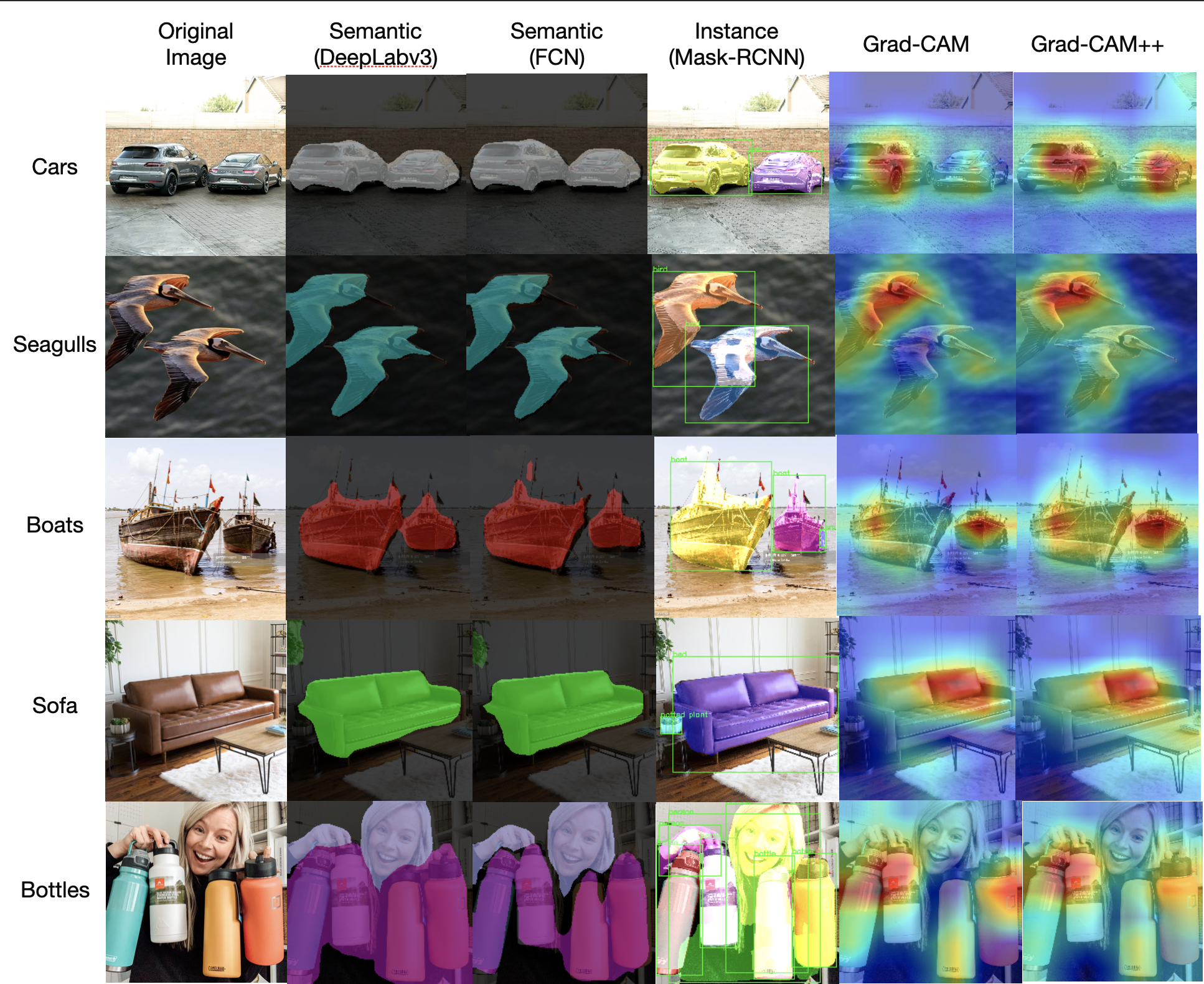
From the image above, we show semantic and instance segmented masks for 5 image categories - cars, bottes, boats, seagulls and sofa. We can observe that semantic fcn maps are coarse and do not fully segment the desired object in the image in contrast to deeplabv3 semantic maps. However, instance segmented maps are very smooth in terms of their segmentation results. Not only are the individual instances of similar category detected but masked uniquely. If we observe the Grad-CAM visualizations we see the desired object highlighted with the heatmap. However, Grad-CAM maps are more focussed on highlighting single instances and fail in case of multiple instances. Grad-CAM++ fills this caveat and highlights or attends to multiple instances of same object in the image. For instance, observe the car image in the first row. Grad-CAM++ clearly highlights both cars while Grad-CAM fails to do so.
In case of the boat image, semantic FCN highlights the mast of the ship with a small red patch. Likewise, mask-rcnn based instance maps too mask both the boats uniquely and entirely with great detail. This can be verified by the Grad-CAM++ heatmaps, where we can see the a significant amount of focus being given to entire boat along with its mast not to forget the smaller boat as well. As for seagulls, Grad-CAM++ maps show a larger coverage in terms of attention. Both the seagulls have their body and feathers as part of the heatmap visualization. However, Grad-CAM shows just one of them being properly looked at by the network. The instance segmentation map is once again very crisp and precise while semantic maps are coarse.

Grad-CAM and Grad-CAM++ visualizations of ResNet-101 network for layer4 along with Segmentation outputs
¶
Let’s look at another set of examples which will help us establish that the segmentation maps are consistent with the Grad-CAM visualizations. Consider the above image. Given an image of people very close to each other, semantic segmentation does a single mask as usual, nothing fancy. However, instance segmentation failed to identify the instances as 2 separate entities. Grad-CAM and Grad-CAM++ maps too show a singular attention at the center of the image, rather than 2 separate focus maps as shown in the car and the boat cases we discussed above. This shows that Grad-CAM and Grad-CAM++ visualizations are consistent with the Segmentation maps output.
Let’s look at another image, an image of skunks. Since skunks do not belong in the 20 categories on which the Semantic Segmentation models are trained on, we observe that DeepLabv3 and FCN classify most of it as background except a coarse patch. However, once again, instance segmentation fails to uniquely mask the 2 animals and considers it as 1, supposedly assuming the left skunk to be the original one with its head and the body spreading across the right half of the image. This can be verified by the CAM visualizations on the right where both images show attention given to the left skunk. We can clearly conclude from these two instances that entities which are too close to each other of the same category sometimes becomes hard for the network to be distinguished. In our case, the humans and the skunks were too close to be considered as a separate entity.
Lastly, one final image just for concluding our observations. An image of both the human and a horse. If 2 separate entities are given, are segmentation and CAM maps consistent. As can be seen, both Semantic and Instance maps uniquely mask both separate entities. However, if you notice Grad-CAM and Grad-CAM++ both highlight the horse since it identifies it as the horse. This is quite accurate considering that Grad-CAM and Grad-CAM++ were trained on 1000 IMAGENET categories and can classify a human, while Instance segmentation was only trained on 80 categories. The models are interpretable and their behaviour seems to be consistent with that the network sees.
The above three decisive observations are particularly trustworthy, since we used ResNet-101 for our Grad-CAM and Grad-CAM++ visualizations. If you do recall, our segmentation models too had ResNet backbone architecture and hence the results seem to be explainable in itself.